Are Capsule Networks Still Relevant or Headed for the Trash?
Published:
Capsule Networks (CapsNets) burst onto the scene in 2017 amid claims that they could revolutionize deep learning. Introduced by Geoffrey Hinton and colleagues, CapsNets were hyped as a solution to limitations of Convolutional Neural Networks (CNNs) in capturing spatial hierarchies 1 2. Early media dubbed them “potentially revolutionary” and an “amazing breakthrough,” raising expectations that capsules might replace or augment CNNs in vision tasks 1. Yet, a few years later, one must ask: have capsule networks lived up to their promise, or are they fated to join the scrap heap of AI ideas that never caught on? In this post, we take a deep dive into what CapsNets are, how they differ from CNNs and Transformers, the latest research developments (2021–2025), real-world applications (or lack thereof), and why they haven’t achieved mainstream adoption so far. We’ll weigh their theoretical strengths against practical realities to assess whether these once-promising networks are on the verge of obsolescence or still hold future potential.1
What Are Capsule Networks?
Capsule Networks are a type of neural network designed to encode hierarchical relationships in data, aiming to address the shortcomings of CNNs in preserving spatial information 2. In a CapsNet, neurons are organized into small groups called “capsules,” where each capsule outputs a vector (or matrix) of parameters rather than a single scalar. This vector is meant to represent not only the presence of a feature but also properties like pose (position, orientation, scale) of that feature. In essence, a capsule’s output encodes what is present and how it is oriented or located. The length or magnitude of the vector often signifies the probability that a particular entity exists, while the orientation of the vector encodes the entity’s state (the “instantiation parameters” of the feature) 3. This structure contrasts with standard neurons in a CNN, which output a single activation value per feature and largely lose detailed pose information after pooling.
A core innovation of CapsNets is the concept of dynamic routing by agreement. Instead of simply passing outputs forward via fixed weights, capsules dynamically decide which higher-level capsule should receive their information based on how well their “prediction” agrees with the higher-level capsule’s input 4. In practice, each capsule in one layer will predict outputs for capsules in the next layer; an iterative routing algorithm then adjusts coupling coefficients between capsules such that lower-level capsules send their output to the most appropriate higher-level capsule. This routing-by-agreement means that if several low-level capsules “agree” on the presence and pose of a higher-level entity, their outputs reinforce each other to activate the corresponding parent capsule 4 5. For example, if capsules detecting edges or facial features all predict they align to form a face, the face-capsule in the next layer will strongly activate. Figure 1 illustrates a simple CapsNet architecture, where convolutional feature maps feed into primary capsules, which are then dynamically routed into output capsules representing detected classes.
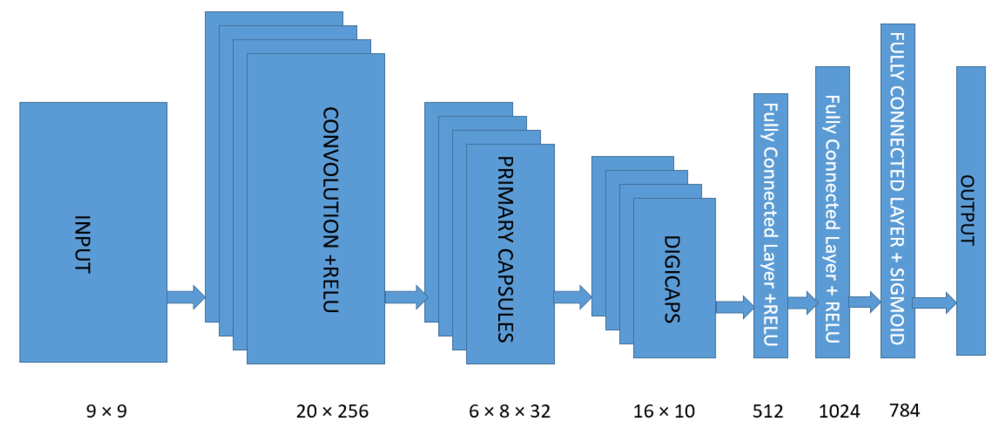
Figure 1: An example Capsule Network architecture (CapsNet) for MNIST digit recognition, as introduced by Sabour et al. 2017 6. After initial convolution layers, Primary Capsules (groups of neurons whose outputs are 8-dimensional vectors) feed into Digit Capsules (one 16-D capsule per output class). A dynamic routing algorithm determines how primary capsules send their outputs to each digit capsule based on agreement. Additional fully-connected layers can decode capsule outputs (e.g. for reconstruction). In this way, the network encodes both the presence of a feature and its pose parameters at each layer.
Another key idea is equivariance. CapsNets aim to be equivariant to transformations: when an input object changes (e.g. rotates or shifts), the internal capsule representations change in a predictable, “corresponding” way rather than just losing that information. In other words, a capsule doesn’t try to be invariant to rotations/affine transformations; instead it encodes the transformation in its output. “Equivariance is the detection of objects that can transform into each other,” as one explainer puts it 4. For instance, a capsule might output a vector indicating “face present, rotated 20° to the right.” If the face in an image were rotated 20° left instead, the capsule would output a vector rotated in the opposite direction, capturing that change 4. This is different from CNNs, which typically achieve invariance by using pooling or data augmentation – i.e. a CNN tries to fire the same way for a face whether it’s tilted or not, but it does not explicitly represent the degree of tilt. Hinton’s view was that by being equivariant and encoding pose in the activations, CapsNets could generalize better to new viewpoints with less training data 4. In effect, a single capsule can handle multiple variations of a feature, whereas a CNN might need many filters or training examples to cover those variations.
To summarize the core features of Capsule Networks:
- Vectors (or Matrices) as Outputs: Each capsule outputs a set of parameters describing a feature’s presence and pose, rather than a single scalar activation 3. This allows representation of part-whole relationships (e.g. parts of a face relative to the whole face).
- Dynamic Routing by Agreement: Capsule layers are connected via an iterative routing mechanism that learns to send lower-level capsule outputs to appropriate higher-level capsules based on agreement, rather than fixed pooling 5. This is intended to “route” information along the parse-tree of object parts to wholes.
- Equivariance to Transformations: Capsule representations change in a structured way when the input is transformed (translation, rotation, etc.), preserving information like orientation and scale. The network “knows” how an object is transformed, instead of discarding that information.
- Inverse Graphics Perspective: CapsNets have been described as performing “inverse graphics,” trying to infer the latent parameters of objects (like a graphics renderer in reverse) 2. By explicitly modeling part-whole relationships and poses, the network mimics how one might deconstruct an image into a hierarchical scene description.
With these innovations, the initial CapsNet paper demonstrated compelling results on simple tasks – notably, achieving state-of-the-art on MNIST digit recognition with far fewer parameters than a comparable CNN, and showing robustness to affine perturbations (e.g. it handled rotated or overlapping digits better than CNNs) 7. This early success, combined with Hinton’s reputation, led to excitement that capsule networks might overcome CNN limitations in one elegant swoop.
Capsule Networks vs. Convolutional Neural Networks (CNNs)
CNNs have been the cornerstone of computer vision for a decade, excelling at pattern recognition through layered convolution and pooling. What advantages were capsule networks supposed to have over CNNs? The main critique of CNNs is that “valuable information, such as object pose and location, is discarded in the pooling process” 2. Pooling creates translational invariance by reducing resolution, but at the cost of losing the precise spatial relationships between features. For example, a CNN might detect nose, eyes, and mouth features in an image but, without explicit positional encoding, could be fooled into thinking they form a face even if arranged nonsensically (imagine a Picasso-style face with jumbled features) 4. A classic CNN will activate for the presence of those features, yet fail to realize the spatial configuration is wrong, because it doesn’t inherently encode relative positions. This can yield bizarre false positives. CapsNets directly address this by preserving part-whole spatial relationships at each layer – a mouth capsule “knows” its pose relative to an expected face capsule, for instance, and will only strongly activate the face capsule if the geometric arrangement matches. In theory, this gives better generalization to viewpoint changes or novel poses. A capsule detecting a familiar object from a new angle can inform a higher capsule “I see object X but rotated/flipped,” instead of forcing the network to learn separate filters for each variation 5. Researchers argued this could make capsules far more data-efficient and robust than CNNs, which often require extensive data augmentation to handle rotations, scale changes, etc..
Another purported strength of capsules is handling overlapping or occluded objects. Hinton’s capsule paper showed that dynamic routing can implement a form of “explaining away” – if one capsule strongly explains a set of pixels as one object, other capsules won’t over-claim those same pixels 6. This could help segment or distinguish multiple objects in an image without confusion, whereas CNN feature maps might mix signals in cluttered scenes. In one experiment, CapsNets significantly outperformed CNNs on overlapping digit classification, essentially by segregating the “digit 5” and “digit 3” when they overlapped, thanks to the routing mechanism.
On paper, capsule networks have several theoretical advantages over CNNs:
- Preservation of Spatial Hierarchies: CNNs are good at local feature detection, but ignore global configuration (e.g. scrambled face parts can trick them) 4. CapsNets explicitly model the hierarchy of parts to wholes, preserving spatial configuration through capsule vectors and routing.
- Fewer Parameters (Efficiency): Because capsules can represent many variations of a feature, CapsNets might not need as many redundant filters. One study noted that a properly designed capsule network could achieve competitive results “with only 2% of the original CapsNet parameters” by efficiently encoding transformations 8. In principle, a capsule should handle, say, all rotations of a feature with one set of parameters (via its pose matrix), whereas a CNN might require multiple filters or a bigger network to learn the same.
- Better Generalization from Less Data: By learning equivariant representations, CapsNets were argued to generalize to new viewpoints or minor distortions without seeing as many examples in training. In contrast, CNNs often need extensive data augmentation or larger datasets to cover all transformations, since they lack an intrinsic mechanism to handle them.
- Robustness to Adversarial Attacks: Some early reports speculated or observed that capsules might be harder to fool with adversarial perturbations than CNNs, because the attack would need to consistently spoof an entire vector agreement rather than single scalar activations. (This point remains debated and we’ll revisit it with recent research.)
However, these advantages came with serious caveats. In practice, the original CapsNet was only proven on small-scale tasks (e.g. MNIST and small image datasets). Traditional CNNs, meanwhile, were rapidly evolving with techniques to mitigate their weaknesses. For example, the lack of rotation invariance in CNNs can be addressed via data augmentation (rotating images in training) or specialized layers, and pooling isn’t the only way to preserve spatial info (architectures like ResNets and vision transformers maintain higher-resolution features longer). In fact, many limitations of CNNs identified in 2017 were gradually overcome by “brute force” improvements: more data, deeper networks, and architectural tweaks. With sufficient training, CNNs “function well enough” on tasks even if they don’t explicitly parse object hierarchies. Thus, the real-world performance gap between a well-tuned CNN and a CapsNet often did not materialize in a decisive way.
Moreover, CNNs enjoy a mature ecosystem. By the late 2010s, practitioners could pull off-the-shelf CNN backbones (ResNet, Inception, etc.) pre-trained on massive datasets, and fine-tune them to new tasks with ease. This leveraging of transfer learning gave CNNs a huge practical edge. In contrast, CapsNets had no such library of pre-trained models – every experiment started from scratch, a high barrier for widespread use. The difficulty of training CapsNets (as we’ll discuss) further meant that in many benchmark comparisons, a simpler CNN could achieve equal or better accuracy with much less effort. In sum, while capsules hold theoretical appeal over CNNs in representing object compositionality and pose, CNNs proved to be “good enough” and easier to scale for most applications. As one analysis wryly noted, “Capsnets quickly became an unwieldy solution in search of a problem”, as CNNs + tricks kept improving and rendering the capsule’s advantages less compelling.
Capsule Networks vs. Transformers
In parallel to capsule research, the late 2010s and early 2020s saw the rise of Transformer architectures – first dominating NLP and later making inroads into vision (Vision Transformers, ViTs). Transformers are very different in design from capsules (they use attention mechanisms rather than routing), but it’s worth comparing their capabilities and whether transformers addressed some of the same issues that capsules aimed to solve.
Vision Transformers (ViT) treat an image as a sequence of patches and use self-attention to model relationships between patches. Unlike CNNs that have a strong inductive bias for locality (nearby pixels) and translation invariance, transformers are more agnostic – any patch can potentially attend to any other, capturing long-range dependencies. This global receptive field means a ViT can learn spatial relationships and configurations, but it does so in a data-driven way without being explicitly told about hierarchies. In theory, capsules have a more structured approach: they force a part-whole hierarchy and coordinate transform through the routing algorithm. A transformer has to learn any such structure implicitly through attention patterns. The upside is that transformers are highly flexible and scalable – given enough data and compute, they can discover the relevant relationships on their own, and they benefit enormously from transfer learning (pre-training on huge datasets). By 2021, ViTs matched or surpassed CNN accuracy on large vision benchmarks by training on very large datasets, albeit at the cost of heavy computation.
One could argue that some of the capsule network’s goals are achieved in modern architectures: for example, Mixture-of-Experts (MoE) models and multi-head attention both involve dynamically routing information. In fact, the capsule idea of “activating subsets of the network based on input” is conceptually related to what multi-head self-attention or MoEs do – different inputs activate different heads or experts. Hinton himself noted the connection that capsules are like a routing procedure to chosen specialists (parts to wholes), while transformers use learned attention to reweight connections between tokens. However, transformers do not enforce an explicit parse-tree or geometric relationship; they excel by brute-force learning of patterns with massive data, and they scale exceptionally well with parallel computation (self-attention can be done efficiently on GPUs/TPUs). Capsules, by contrast, struggled to scale (routing is iterative and not easily parallelized in early forms) and did not see the same investment in large-scale training.
It’s also instructive to compare how each handles transformations: A ViT can learn equivariance or invariance if given data (it might learn to attend to a rotated object’s patches appropriately), but it doesn’t inherently know that “rotated 20°” is the relationship – it might just learn that pattern in weights. A capsule explicitly encodes “rotated 20°” as a parameter. In theory, that’s cleaner and more interpretable. In practice, though, transformers have proven far more effective on complex data. No capsule network to date has matched the performance of transformer-based models on large-scale tasks. For example, there is no capsule analogue of GPT or a ViT beating state-of-the-art ImageNet results; those breakthroughs came from transformers and CNN hybrids, not capsules.
Interestingly, researchers have started to merge ideas from capsules with attention in recent works. Some have proposed capsule networks that use attention mechanisms in place of iterative routing – essentially treating coupling coefficients as outputs of a self-attention operation. For instance, a 2021 study introduced “Efficient-CapsNet” which replaces dynamic routing with a non-iterative, highly parallelizable routing via self-attention, making the capsule aggregation faster 8. And a very recent 2025 work describes a “Spatially Invariant Self-Attention Capsule Network (SISA-CapsNet)” that uses self-attention to cluster feature capsules into class capsules 9. By integrating a transformer-like attention module, these models aim to get the best of both worlds: the interpretability and structured representation of capsules, plus the efficiency and parallelism of attention. Early results show that such hybrid approaches can improve capsule performance on certain tasks, and even provide better interpretability. For example, SISA-CapsNet explicitly forms feature capsules for distinct image regions and then uses attention to weight their importance for the final classification, yielding an “interpretable classification framework” where one can see which regions contributed to the decision 9.
In summary, transformers largely stole the spotlight in the years that capsules were trying to gain traction. Transformers solved critical problems in sequential data (NLP) and scaled up in vision, whereas capsules did not demonstrate a clear win on problems that couldn’t be handled by other means. Nonetheless, the conceptual innovations of capsules continue to influence research. By borrowing ideas from both capsules and transformers, new architectures might yet capture the benefits of part-whole modeling within the powerful attention-based frameworks.
Latest Research on Capsule Networks (2021–2025)
Although capsule networks didn’t become mainstream, research has continued in the academic community to improve and understand them. From 2021 through 2025, several notable developments occurred:
Improved Routing Algorithms: Recognizing that the original dynamic routing was slow and hard to scale, researchers proposed alternatives. One example is using self-attention for routing (as mentioned above) to eliminate the iterative agreement loops 8. Others devised variations like EM routing (Hinton’s follow-up, treating routing as an Expectation-Maximization process 10), inverse-temperature annealing to stabilize training, or even non-routing approaches. A 2021 Scientific Reports paper introduced a capsule network with a novel one-shot routing that was highly parallelizable, allowing a CapsNet with only 160k parameters to achieve state-of-the-art results on several small datasets. The focus here was on efficiency – demonstrating that capsules can be lightweight if we remove the biggest computational bottleneck. Similarly, in 2023–2024, works like “Capsuleformer” and “Graph Capsule Networks” integrated graph algorithms or transformers to make routing more feasible at scale. The trend is towards making capsule-like computations more compatible with modern hardware and large data.
Deeper Capsule Architectures: Early CapsNets were essentially two layers of capsules (primary capsules -> output capsules). Stacking many capsule layers was difficult (vanishing gradients, exponentially many routing paths, etc.). Some researchers attempted to build “deep capsule networks” with more layers. For instance, “PT-CapsNet” (Prediction-Tuning CapsNet) explored a method to train deeper capsule models by passing predictive feedback between layers 11. While a true very-deep CapsNet is still not common, these attempts are probing whether capsules can form multi-level hierarchies beyond simple part-whole (e.g., part -> object -> scene contexts). Thus far, depth remains limited; the consensus is that capsules haven’t scaled to the depth of typical CNNs. In fact, a 2023 study provided a theoretical explanation: it argued that “no work was able to scale the CapsNet architecture to more reasonable-sized datasets” and concluded that fundamental issues prevent scaling 7. Specifically, they found that the intended parse-tree hierarchy doesn’t actually emerge in current implementations, and that vanishing gradients cause many capsules to “starve” (never get trained/active) in deeper networks. This means as you add layers, capsules might die out or fail to route information effectively – a serious open question if capsules are ever to handle complex data.
Robustness and Adversarial Studies: One appealing idea was that capsules, by virtue of agreement-based routing, might resist adversarial perturbations or noise better than CNNs. Some research supports this: capsules need a coordinated change in a whole vector to fool, which could make trivial pixel attacks less effective. However, other studies showed this robustness can be overstated. For example, Gu et al. (2021) tested CapsNets vs CNNs under various adversarial attacks and reported that “Capsule network is not more robust than convolutional network” in their experiments. Additionally, attacks specifically targeting the routing mechanism (so-called “vote attacks”) were devised to break capsules by disrupting the agreement process 2. In short, while caps may not be quite as fragile as plain CNNs on some distortions, they are not invincible – adversaries can still find ways to fool them, and if anything, the less widespread use of capsules means they’ve been less battle-tested in security-critical applications. Robustness remains an active research angle (e.g., coupling capsules with probabilistic routing or Bayesian approaches to handle uncertainty).
Applications in New Domains: Researchers have explored capsule networks beyond simple image classification. From 2021 onward, there have been papers applying capsules to medical imaging (e.g. tumor detection, COVID-19 X-ray diagnosis) with claims of improved accuracy on small datasets 12 13, to NLP tasks (text classification, sentiment analysis) by using capsules to capture phrase structures, and even to 3D data or graphs (treating parts of a 3D shape as capsules). A 2022 work introduced “CapsuleGraph Transformers” for multimodal emotion recognition, combining capsule networks with graph neural nets to capture relationships in multimodal data 14. Another intriguing direction is using capsules for generative models – e.g., a 2022 paper “Capsule Networks as Generative Models” investigated capsule-based variational autoencoders 15. While these domain-specific uses show the versatility of the capsule concept, none has yet become a breakout “killer app.” In most cases, capsules offer a marginal gain or an interesting insight, but also bring the overhead of complex training. For instance, in medical image analysis, some studies note capsules perform comparably to CNNs but with potentially better generalization on rotations 16, which is useful in medical scans where orientation can vary. But training capsules on larger medical image sets remains challenging due to computational cost, so their use is often limited to research prototypes.
Understanding Capsule Representations: Some very recent work (2024–2025) is focused on interpreting what capsules learn. Since capsules were touted as more interpretable (each dimension of a capsule might correspond to a human-meaningful parameter like “angle” or “scale”), researchers are examining if this is true. The SISA-CapsNet (2025) explicitly claims an interpretable design by mapping image regions to capsules and using attention to see which regions activate class capsules 9. Other studies attempt to visualize capsule outputs or align them with known transformations. The verdict so far: capsules do encapsulate pose information (you can, for example, change a capsule’s vector and meaningfully rotate/reconstruct an image in some setups), but interpreting high-dimensional capsule vectors is not trivial. Ironically, one survey listed “limited interpretability” as a challenge for CapsNets, noting that while capsules pack more information, understanding how each element of a capsule contributes to the final decision is still “not straightforward”. In short, the promise of clear interpretability is only partially realized; it remains an open research area to align capsule dimensions with semantic factors in a reliable way.
In summary, 2021–2025 research on capsule networks has been rich, addressing their weaknesses and exploring new frontiers. There have been improvements (faster routing, small successes in niche domains, integration with attention for scale) and sobering findings (theoretical limits to scaling, mixed results on robustness). Key open questions include: Can capsule networks be scaled up to ImageNet-level complexity? Can training be stabilized for deeper capsule stacks? Are there practical tasks where capsules decisively outperform other models? These are actively discussed in recent literature, with no clear answers yet.
Real-World Applications and Industrial Use
Given the flurry of research, one might wonder how many real-world systems are using capsule networks today. The honest answer is: hardly any, at least not in mainstream industry applications. Unlike CNNs (ubiquitous in everything from photo tagging to autonomous vehicles) or transformers (powering modern NLP and vision APIs), capsule networks have largely stayed in the research realm. There are a few reasons for this lack of industrial adoption:
Computational Cost and Scalability: In practice, early CapsNets were far slower and more memory-hungry than CNNs for comparable tasks 1. The dynamic routing process is iterative and not easily accelerated on standard GPU operations, making inference and training cumbersome. For large images or large datasets, this was a deal-breaker. Companies that need to process millions of images efficiently weren’t going to invest in a method that might be 10× more expensive unless it promised >10× better performance – which it did not. Even with later optimizations, capsules remained less efficient for high-resolution inputs. Scalability issues (both algorithmic and implementation-wise) meant that one couldn’t simply take a capsule network and plug it into, say, an ImageNet training pipeline and expect good results within reasonable time. This has started to change with newer routing mechanisms 8, but those improvements are very recent and yet to be widely reproduced.
Tooling and Ecosystem: The deep learning ecosystem is built around well-optimized layers and architectures. CNNs and transformers benefit from highly optimized library support (e.g. cuDNN for convolutions, XLA optimizations for attention). Capsule networks, being unconventional, had no built-in support and required custom implementation of routing algorithms. This made them less accessible to practitioners. As one source noted, “practical implementations and widespread adoption are still in nascent stages, thereby limiting availability in mainstream AI frameworks” 17. For a long time, there wasn’t a capsule layer in TensorFlow or PyTorch – only third-party code. Without easy-to-use tooling, most engineers didn’t bother experimenting with capsules, especially when CNNs were yielding state-of-the-art results with far less hassle.
Lack of Pre-trained Models: A major advantage in vision and NLP today is the availability of pre-trained models that you can fine-tune to your task (e.g. ResNet on ImageNet, or CLIP and ViTs pre-trained on huge data). No such pre-trained capsule networks exist in the wild. Every application of CapsNet tends to start training from scratch on a relatively small dataset, which is not only time-consuming but often results in worse performance than simply fine-tuning a pre-trained CNN. This absence of a transfer learning story for capsules made them unattractive for industry adoption. (Notably, some recent work on self-supervised capsule pre-training for medical images 12 is trying to address this, but it’s early and not mainstream.)
Comparative Performance: Perhaps the biggest factor: Capsule networks did not demonstrate a clear must-have advantage in real-world benchmarks. If CapsNets had, for example, blown away CNNs on ImageNet or significantly improved efficiency, industry would have paid attention despite the complexity. But as of 2025, no flagship result screams “capsules are superior here.” Instead, we see incremental improvements or niche wins: a capsule model might slightly outperform a CNN on a small rotated-MNIST dataset, or handle an edge case a bit better, but these are not game-changing for broad applications. Meanwhile, CNNs and transformers kept improving. A telling quote: “While theoretically elegant, capsnets did not offer the real-world performance advantage over CNNs that would justify all this additional work”. In other words, why use a complicated new thing when the old thing (with some tweaks) works just as well or better? This sentiment largely explains why many research groups moved on – there was no killer app where capsules clearly dominated.
Community and Momentum: The AI community can sometimes coalesce around a promising idea and rapidly advance it (as happened with transformers), or it can collectively lose interest if early attempts falter. Capsule networks had a lot of hype initially, but as results proved hard to reproduce or scale, the community’s excitement waned. Transformers emerged around the same time and quickly showed breakthroughs, so talent and attention flowed in that direction. With fewer researchers pushing on capsules (relative to the massive effort behind transformers or CNNs), progress slowed. A lack of community support also meant fewer tutorials, fewer libraries, and less shared knowledge, reinforcing the barrier to entry. It became a bit of a vicious cycle: few successes led to fewer new researchers adopting caps, which led to even fewer successes.
Use Cases Maybe Too Niche: The theoretical strengths of capsules (handling viewpoint changes, parsing object composition) are important, but many practical applications either have other ways to solve those issues or don’t require such fine-grained understanding. For instance, data augmentation and larger CNNs have been sufficient to handle rotations in most image tasks. If someday we need AI that truly understands 3D spatial arrangements from images (e.g. for reasoning about scenes), capsules might shine – but alternative approaches like neural radiance fields (NeRFs) or transformers with 3D positional encoding are also vying for that domain. It’s possible that the problems capsules are best suited for just haven’t been the top priority in industry yet.
That said, it’s not all bleak. Some domains have experimented with capsules due to their specific needs. In medical imaging, data is limited and orientation can vary (e.g. MRI slices), so a method that generalizes better from less data is attractive. A 2023 survey of capsule use in medical image analysis found many papers reporting improved diagnostic accuracy using CapsNets 16. However, these are typically research prototypes, not deployed hospital systems – at least not yet. Another area is reinforcement learning for vision (where an agent needs to understand objects in a scene; capsules could help it recognize objects under different views). And interestingly, the robotics community exploring 3D object understanding and inverse graphics has an eye on capsule-like representations to better infer object properties from sensory data. For example, there’s work on using capsule networks to control a camera or robot by understanding the scene composition (though again, nothing widespread in products).
To date, no major tech company has announced that “Capsule Networks are running in our vision pipeline” to the best of public knowledge. If anything, capsules serve as an inspirational idea that occasionally informs other models. For instance, some computer vision systems incorporate the idea of part-based representations (common in older computer vision too), and one could view “coord-conv” or equivariant CNNs as incorporating a bit of the capsule spirit by retaining spatial info. But a full-blown capsule network is rarely the first choice outside academia.
Why Haven’t Capsules Achieved Mainstream Adoption?
From the above, we can distill several key reasons capsules have not (yet) taken off in mainstream AI practice:
Higher Complexity & Compute Demand: “They were significantly more computationally intensive than CNNs”. Dynamic routing adds overhead that makes CapsNets slower and harder to parallelize. This made it hard to scale to large datasets or high-resolution images. CNNs and Transformers, in contrast, leverage highly optimized operations and scale well with big data/hardware. The computational cost vs. benefit trade-off for capsules has so far not favored them.
Training Difficulties: Capsules proved sensitive to initialization and hyperparameters, requiring careful tuning. Many researchers found them finicky to get working – a far cry from the relative plug-and-play of established architectures. Recent studies point to issues like vanishing gradients and “capsule starvation” in deeper capsule networks, meaning many capsules don’t learn effectively as networks grow. This brittleness made experimentation slower and success less guaranteed. Simply put, it was easier to get a high-performing model with other methods.
Lack of Infrastructure & Pre-training: With minimal framework support and no pre-trained models, CapsNets had to start from scratch each time. This “standing start” meant huge effort for any new application. In the fast-paced AI industry, solutions that can leverage transfer learning and existing tooling win out. Capsules arrived to find an ecosystem already deeply invested in CNNs/transformers, and they didn’t integrate smoothly.
No Overwhelming Superiority: Perhaps most damning, capsules haven’t shown a compelling performance edge in practice. If CapsNets had, say, doubled accuracy on a crucial task, the field would have endured the complexity. But improvements were incremental or in domains that weren’t pressing for industry (like small-digit datasets). Meanwhile, CNNs kept improving their supposed weaknesses (through brute force or clever tweaks). This made capsules look like an elegant but unnecessary complication. They solved a problem that could be solved in other simpler ways.
Community Momentum Shift: The timing was unfortunate – capsules appeared just as the “Attention is All You Need” revolution began. Transformers delivered huge wins in NLP and then vision, drawing researchers, funding, and mindshare. Capsules, lacking a killer app or big win, gradually lost the spotlight. With fewer people working on them, progress slowed, creating a self-reinforcing cycle of waning interest.
Practical Limitations: Other niggling issues include model size (capsule outputs are larger vectors, which can blow up network size if not carefully constrained), lack of interpretability tools, and reports of being “sensitive to small variations” in input in unexpected ways. For example, one might expect capsules to handle slight changes well, but if the dynamic routing incorrectly routes even a subtle change, it could cause a different outcome – some early users found CapsNets could still be brittle in weird corner cases. These kinds of quirks further made practitioners hesitant to trust a relatively unproven technique.
In essence, the deck was stacked against capsule networks in terms of immediate adoption. It’s a classic story in technology: a new idea promises to fix some issues, but if the incumbents (CNNs/transformers) can patch those issues faster than the new idea can mature, the new idea might never get a foothold. As one retrospective put it, a lot of the limitations capsule networks targeted were “fixable by specific techniques or improved organically” in CNNs as hardware and data improved, leaving capsules as a solution looking for a problem that wasn’t urgent enough.
Conclusion: The Promise vs. Reality of Capsule Networks
Capsule Networks embodied a beautiful idea: mimicking the human visual system’s way of composing and understanding objects. They introduced the field to concepts of equivariance and dynamic routing that have undoubtedly enriched how researchers think about representation learning. In theory, capsules offer a more structured, interpretable representation of images, potentially requiring less data to generalize new viewpoints. The early hype was not unfounded – CapsNets did demonstrate excellent performance on toy problems and sparked a wave of research into more powerful and flexible architectures.
However, the practical reality has been that capsule networks so far failed to outperform simpler architectures by a wide enough margin to justify their complexity. They arrived at a time when CNNs were ascendant and soon were overshadowed by transformers, both of which enjoyed far greater investment and solved pressing challenges. The result is that, as of 2025, capsule networks remain a niche topic. Promising – yes, in concept. Mainstream – not yet.
Does this mean capsule networks are “about to end up in the trash”? Not exactly. It’s true that the initial wave of hype has died down, and one might cynically say capsules are “gone but not forgotten”. But research has not abandoned them. Instead, capsules are evolving quietly: the latest works are hybridizing capsules with attention mechanisms, addressing their weaknesses, and finding specific domains where their properties can be useful (like interpretability in critical applications). It’s possible that capsule-like ideas will resurface in new forms. In fact, parts of the capsule philosophy (dynamic selection of pathways, equivariant representations) are finding their way into modern architectures – sometimes under different names. For instance, equivariance is an active area (e.g. Group Equivariant CNNs, pose-aware networks) and dynamic routing appears in Mixture-of-Experts and adaptive computation efforts. The original CapsNet design might not prevail, but its DNA might live on.
For capsule networks to avoid the trash heap and become more widely adopted in the future, a few things might need to happen: a breakthrough in scalability (so they can handle big data efficiently), a killer application where their part-whole reasoning is essential (perhaps in 3D vision, or a task where data is extremely limited but variations are high), or incorporation into a larger successful framework (imagine a Vision Transformer that uses capsule layers internally for added structure). Any of these could rekindle interest.
In conclusion, Capsule Networks represent a case of significant theoretical promise grappling with practical headwinds. At their core, they address a real gap – the ability of neural nets to understand objects beyond just shallow patterns. That gap still exists in some sense; our current models are incredibly powerful, but often still brute-force learners. Whether capsules in their original form will be the solution is unclear. They may not become the next ubiquitous architecture as once hoped, but the problems they were trying to solve are important, and the ideas they introduced have already influenced other advancements. Rather than ending up “in the trash,” capsules might simply be recycled – transformed and integrated into the next generation of AI models, ensuring that the legacy of those promising ideas continues to inform the evolution of deep learning.
References:
Air Street Press, Benaich, N., & Chalmers, A. (2024, May 1). Who remembers capsule networks? Retrieved 16 May 2025, from Air Street Press website: https://press.airstreet.com/p/who-remembers-capsule-networks ↩ ↩2 ↩3 ↩4
M. U. Haq, M. A. J. Sethi, and A. U. Rehman, ‘Capsule network with its limitation, modification, and applications—A survey’, Mach. Learn. Knowl. Extr., vol. 5, no. 3, pp. 891–921, 2023. ↩ ↩2 ↩3 ↩4 ↩5
Ross, M. (2017, November 14). A Visual Representation of Capsule Network Computations. Retrieved 16 May 2025, from Medium website: https://medium.com/@mike_ross/a-visual-representation-of-capsule-network-computations-83767d79e737 ↩ ↩2
“Understanding Dynamic Routing between Capsules (Capsule Networks)”. (n.d.). Retrieved 16 May 2025, from Github.io website: https://jhui.github.io/2017/11/03/Dynamic-Routing-Between-Capsules/ ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7
“Understanding Matrix capsules with EM Routing (Based on Hinton’s Capsule Networks)”. (n.d.). Retrieved 16 May 2025, from Github.io website: https://jhui.github.io/2017/11/14/Matrix-Capsules-with-EM-routing-Capsule-Network/ ↩ ↩2 ↩3
S. Sabour, N. Frosst, and G. E. Hinton, “Dynamic Routing Between Capsules,” in Advances in Neural Information Processing Systems, Curran Associates, Inc., Oct. 2017, pp. 1–11. doi: 10.48550/arXiv.1710.09829. ↩ ↩2
Mitterreiter, M., Koch, M., Giesen, J., & Laue, S. (2023). Why capsule neural networks do not scale: Challenging the dynamic parse-tree assumption. Retrieved from http://arxiv.org/abs/2301.01583 ↩ ↩2
Mazzia, V., Salvetti, F., & Chiaberge, M. (2021). Efficient-CapsNet: capsule network with self-attention routing. Scientific Reports, 11(1), 14634. doi:10.1038/s41598-021-93977-0 ↩ ↩2 ↩3 ↩4
Li, P., Ru, J., Fei, Q., Chen, Z., & Wang, B. (2025). Interpretable capsule networks via self attention routing on spatially invariant feature surfaces. Scientific Reports, 15(1), 13026. doi:10.1038/s41598-025-96903-w ↩ ↩2 ↩3
Hinton, G. E., Sabour, S., & Frosst, N. (2018). Matrix capsules with EM routing. International Conference on Learning Representations, 1–15. https://openreview.net/forum?id=HJWLfGWRb¬eId=rk5MadsMf¬eId=rk5MadsMf ↩
Pan, C., & Velipasalar, S. (2021). PT-CapsNet: A novel prediction-tuning capsule network suitable for deeper architectures. 2021 IEEE/CVF International Conference on Computer Vision (ICCV), 11996–12005. IEEE. ↩
Yuan, J., Wu, F., Li, Y., Li, J., Huang, G., & Huang, Q. (2023). DPDH-CapNet: A novel lightweight capsule network with non-routing for COVID-19 diagnosis using X-ray images. Journal of Digital Imaging, 36(3), 988–1000. doi:10.1007/s10278-023-00791-3 ↩ ↩2
Gupta, P. K., Siddiqui, M. K., Huang, X., Morales-Menendez, R., Pawar, H., Terashima-Marin, H., & Wajid, M. S. (2022). COVID-WideNet-A capsule network for COVID-19 detection. Applied Soft Computing, 122(108780), 108780. doi:10.1016/j.asoc.2022.108780 ↩
Filali, H., Boulealam, C., El Fazazy, K., Mahraz, A. M., Tairi, H., & Riffi, J. (2025). Meaningful multimodal emotion recognition based on capsule graph transformer architecture. Information (Basel), 16(1), 40. doi:10.3390/info16010040 ↩
Kiefer, A. B., Millidge, B., Tschantz, A., & Buckley, C. L. (2022). Capsule networks as generative models. Retrieved from http://arxiv.org/abs/2209.02567 ↩
El-Shimy, H., Zantout, H., Lones, M., & El Gayar, N. (2023). A review of capsule networks in medical image analysis. In Artificial Neural Networks in Pattern Recognition (pp. 65–80). Cham: Springer International Publishing. ↩ ↩2
Lark Editorial Team. (2023, December 26). Capsule Neural Network. Retrieved 16 May 2025, from Larksuite.com website: https://www.larksuite.com/en_us/topics/ai-glossary/capsule-neural-network ↩